
#AISprint Darija AI: A Community-Driven Platform for Moroccan Darija Translation Dataset - Minority Languages

Tech enthusiast with a strong focus on Linux, Java, Rust, Cloud, and DevOps.
Passionate software developer with more than 4 years of professional experience. Currently, I am an engineering student at ENSET Mohammadia in Big Data & Cloud Computing field.
I am the type of person who enjoys solving problems using technology tools in order to make human lives easier and more valuable.
GitHub Repostory: https://github.com/ElhoubeBrahim/collect-darija
Platform Link: https://darijaai.mlnomads.com
With the recent advancements in human-like interactions achieved by Large Language Models (LLMs) worldwide, one crucial need for building these models in any language is the availability of high-quality datasets. These datasets must represent:
The way native people use the language
A high level of knowledge expressed in the language
A careful curation to prevent harmful biases
This process is particularly challenging and expensive for minority languages spoken only in certain regions.
Moroccan Darija, a unique dialect spoken by over 91% of Moroccan citizens, exemplifies this challenge. This rich linguistic tapestry blends Arabic with influences from Amazigh, French, and Spanish. The complexity and nuances of Darija make it a formidable task for LLM development. While datasets like DODA and AtlassIA have been created, they often fall short of fully capturing the variety of spoken Darija. This limitation is frequently due to:
Restrictive rules in data collection
Limited translation options
Insufficient representation of colloquial usage
Data leaks between Arabic and Moroccan Darija
Creating thorough and precise datasets for Darija poses a major challenge and opportunity in natural language processing and machine translation. It is of utmost importance to develop a Moroccan Darija Large Language Model that truly captures the essence of this language.

To address these challenges, we have developed "Darija.AI," an innovative crowdsourcing platform designed to build a comprehensive Moroccan Darija-English translation dataset. This platform serves multiple purposes:
Translation: Contributors can translate English phrases sourced from the Mozilla Common Voice dataset into Moroccan Darija.
Review and Evaluation: Users can assess and rate previous translations, ensuring quality and accuracy.
Community Engagement: By involving native speakers and language enthusiasts, we capture the true essence and diversity of spoken Darija.
Scalability: The crowdsourcing approach allows for rapid expansion of the dataset, covering a wide range of topics and linguistic nuances.
By leveraging collective knowledge and fostering community participation, Darija AI aims to create a rich, nuanced, and authentic resource for Darija-English translation, paving the way for more accurate and contextually appropriate language models and translation tools.
Technical Architecture
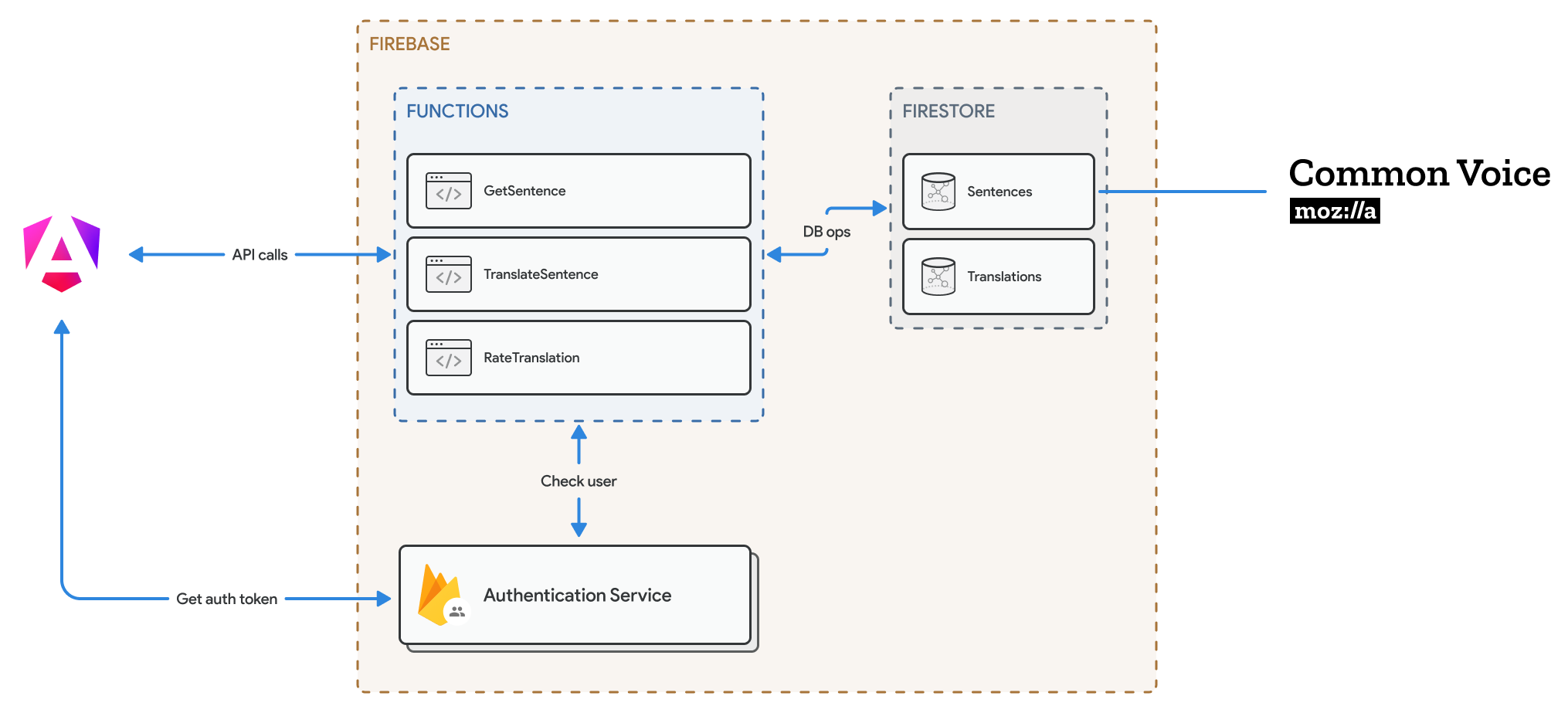
The platform is built on a robust architecture designed to handle large volumes of data efficiently. We used Firebase to handle authentication, data processing, storage, and business logic, ensuring the system's robustness, security, and scalability.
The architecture consists of several key components within the Firebase ecosystem:
Firebase Environment
The entire system is hosted within Firebase, providing a serverless infrastructure that allows for easy scaling and maintenance.Functions
Firebase Functions hosts three key serverless functions:GetSentence: Retrieves sentences for translation from the Sentences collection.
TranslateSentence: Handles the translation process and stores results in the Translations collection.
RateTranslation: Allows users to rate translations, likely updating the Translations collection.
These functions serve as the backend logic for the application, processing requests and interacting with the database.
Firestore
Firebase's NoSQL database, Firestore, is used to store data in three collections:Sentences: Stores original sentences sourced from Mozilla Common Voice.
Translations: Stores translated sentences.
Reviews: Stores the rating of the translated sentences.
Authentication Service Firebase Authentication is implemented to manage user authentication and authorization, ensuring secure access to the platform's features.
External Integration
The system integrates with Mozilla Common Voice, serving as the source for English sentences to be translated into Moroccan Darija.Client Application
The frontend, represented by the Angular logo, suggests an Angular-based web application that interacts with Firebase through API calls.Data Flow
The client app authenticates users and receives an auth token.
It makes API calls to the Firebase Functions for sentence retrieval, translation submission, and rating.
Functions interact with Firestore for data operations.
User authentication is verified before processing requests.
This architecture leverages Firebase's serverless model, allowing for easy scaling and maintenance. The separation of concerns between frontend, backend functions, and data storage provides a modular and flexible system for handling sentence translations and ratings. By utilizing Firebase's integrated services, the platform can efficiently manage user authentication, data processing, and storage, ensuring a smooth and secure experience for contributors engaged in building the Moroccan Darija translation dataset.
Translations Collection
The Darija AI platform employs a diverse range of translation sources to ensure a wide variety of content and contexts. Users are presented with randomly selected English sentences from the Mozilla Common Voice dataset, which they then translate into Moroccan Darija. This approach not only provides a broad spectrum of phrases but also keeps the translation process engaging and dynamic for contributors.
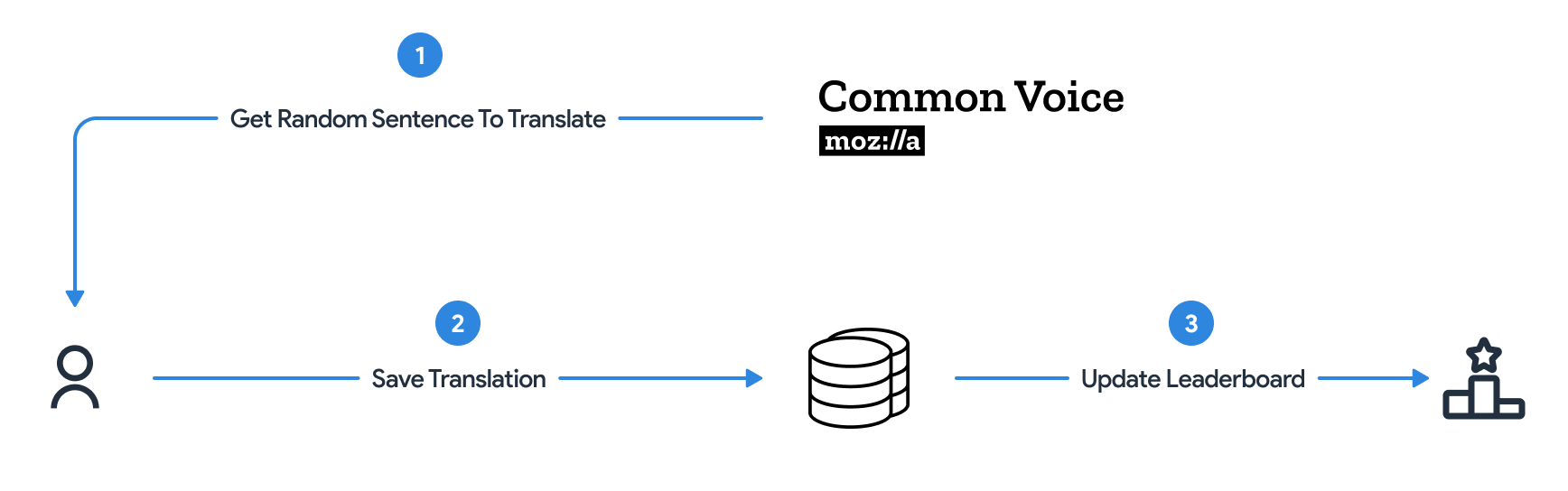
To capture the rich diversity of Darija, we've designed the translation feature without imposing limitations on users' input. Participants have the freedom to write their translations using either Arabic or Latin scripts, ensuring flexibility and inclusivity. Furthermore, there are no restrictions on regional dialects or nuances, allowing for a comprehensive and authentic representation of the language. This unrestrictive approach helps preserve the unique variations and cultural richness of Darija, making our dataset a true reflection of its diversity.
The authenticity of the translations is ensured by engaging native speakers of Moroccan Darija as contributors. All users participating in the translation process are fluent in the dialect, bringing their innate understanding of the language's subtleties and cultural context to each translation. This native-speaker focus is crucial in capturing the true essence of Darija, including its idiomatic expressions, colloquialisms, and regional variations.
To maintain a continuous flow of translations and encourage ongoing participation, the platform immediately provides users with a new sentence to translate after they submit each translation.
We've also incorporated elements of gamification and recognition into the platform to enhance user engagement and motivation. Users earn points for each submitted translation, and these points are reflected in a global leaderboard. This leaderboard showcases top contributors, fostering a sense of healthy competition and providing recognition for valuable contributions to the project. By highlighting the efforts of active participants, we aim to build a strong, committed community of contributors dedicated to the goal of creating a comprehensive Darija-English dataset.
Peer Reviews
To maintain the accuracy and reliability of our dataset, we've implemented a robust peer review and quality assurance process that leverages the expertise of our user community. This innovative approach, which we call Peer-Driven Validation, not only transforms our contributors into active participants in the quality control process but also enables us to harness advanced machine learning techniques, specifically reinforcement learning with human feedback (RLHF).
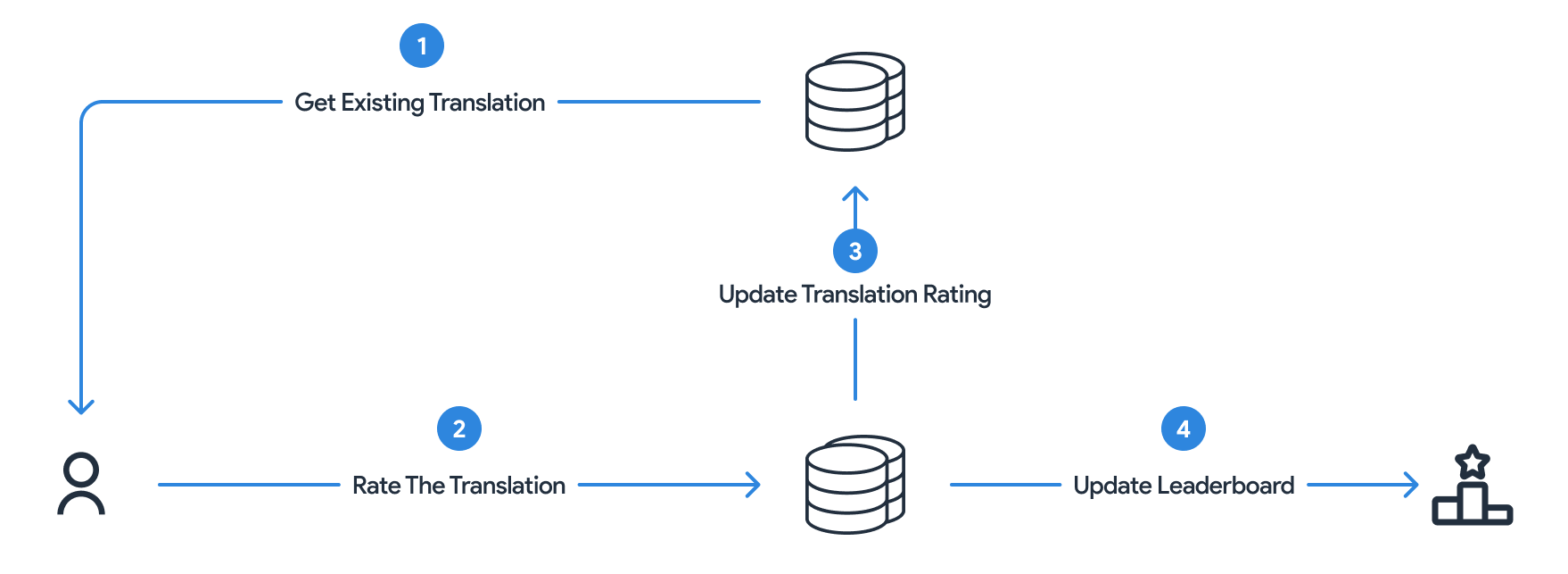
The Peer-Driven Validation process is designed to be both comprehensive and user-friendly. Users are regularly presented with existing translations and transcriptions from the dataset and are asked to assess their quality. This assessment involves rating the accuracy, clarity, and cultural appropriateness of the translations, as well as providing detailed feedback when necessary. By engaging users in this way, we tap into the collective knowledge and intuition of native Darija speakers, ensuring that our dataset remains true to the nuances and complexities of the language.
This iterative review process serves multiple purposes. Firstly, it acts as a powerful filter, helping to identify and correct any inaccuracies or inconsistencies in the dataset. Secondly, it provides valuable insights into the translation process itself, highlighting common challenges or areas of ambiguity that may require further attention or clarification in our guidelines.
Moreover, the human feedback gathered through this process is instrumental in implementing reinforcement learning techniques. By utilizing RLHF, we can train our language models to not just learn from the initial translations but to continuously improve based on the preferences and corrections provided by our user community. This approach allows our models to adapt and refine their outputs over time, learning to generate translations that are more natural, contextually appropriate, and aligned with human judgments.
How to contribute?
The Darija AI project thrives on community engagement and collaboration. We've designed multiple pathways for individuals to contribute, whether they're language enthusiasts or skilled developers. By joining our community, you can play a crucial role in preserving and advancing Moroccan Darija in the digital age.
For Translation Contributors
Becoming a part of the Darija AI community as a language contributor is a straightforward yet impactful process. To begin, simply sign up on our platform at https://darijaai.mlnomads.com. Once registered, you'll have immediate access to our translation interface, where you can start transforming English phrases from the Mozilla Common Voice dataset into rich, authentic Moroccan Darija.
Every translation you provide is a valuable contribution to our growing dataset. Your input not only expands the breadth of our linguistic resource but also enhances the accuracy and cultural relevance of Darija-English translations. As you contribute, you'll see your efforts recognized through our gamified system. Our leaderboard tracks your progress, adding an element of friendly competition and motivation to the translation process.
Beyond translation, we encourage all contributors to engage in our peer review process. By evaluating and providing feedback on translations submitted by fellow contributors, you play a pivotal role in our quality assurance mechanism. This peer-driven validation process is crucial for maintaining the high standards of our dataset and ensures that our translations capture the true essence and diversity of Moroccan Darija.
For Developers
For those with technical expertise in language technology or software development, the Darija AI project offers unique opportunities to contribute your skills. Our project's codebase is open-source and available on GitHub, providing a transparent and collaborative environment for development.
Visit the repo: https://github.com/ElhoubeBrahim/collect-darija
As a developer, your contributions can significantly enhance various aspects of the Darija AI platform. Whether your expertise lies in frontend design, creating intuitive and engaging user interfaces, or in backend infrastructure, optimizing our data processing pipelines, your input can drive meaningful improvements. We also welcome contributions in areas such as machine learning model optimization, particularly in refining our RLHF implementations.
Some key areas where developer contributions can make a substantial impact include:
Enhancing the user experience of our translation and validation interfaces
Optimizing our data storage and retrieval systems for improved performance
Developing new features to gamify the contribution process and increase user engagement
Improving our algorithms for matching reviewers with appropriate content for validation
Implementing advanced analytics to derive insights from our growing dataset
implementing RLHF pipelines to better leverage user feedback in model training
By contributing to the Darija AI project, developers have the opportunity to work on cutting-edge language technology while making a tangible impact on the preservation and advancement of Moroccan Darija. Your work will directly influence the quality of language models and translation tools for this unique dialect, potentially benefiting millions of Darija speakers in Morocco and worldwide.
The Team
The Darija AI project emerged from a confluence of academic curiosity, technological expertise, and community support, embodying the spirit of collaborative innovation in addressing linguistic challenges.

In the heart of Morocco's vibrant tech scene, a team of ambitious Engineers recognized the pressing need for advanced language tools for Moroccan Darija.
Ahmed Houssam BOUZINE a software engineer and a Big Data and Cloud Computing student at ENSET Mohammedia. As part of this project, he was responsible for implementing a review feature that allows users to rate previous translations to ensure translation quality and accuracy. Ahmed developed both the user interface components and the corresponding backend endpoints for this feature.
Tariq EL QESSOUAR a software engineer and a Big Data and Cloud Computing student at ENSET Mohammedia. In this project, Tariq took charge of developing both the frontend and backend components for the leaderboard and history pages. These features allow users to easily monitor rankings and access their historical data, significantly improving the platform's usability and engagement.
Brahim EL HOUBE a software engineer and a student specializing in Big Data and Cloud Computing at ENSET Mohammedia. In the project, he was responsible for developing the backend APIs and various UI components to maintain consistency throughout the app, as well as overseeing the deployment and monitoring of production performance.
Taha BOUHSINE (@tahabsn), a ML/AI Google Developer Expert and organizer of the MLNomads community, provided his expertise which was instrumental in laying the project's foundation. He provided initial guidance, sharing insights gleaned from his extensive experience in the field of machine learning.
Acknowledgment
Google AI/ML Developer Programs team supported this work by providing Google Cloud Credit. #AISprint
We would like to extend our heartfelt appreciation to the following contributors, whose invaluable feedback and contributions were instrumental in refining the platform's requirements and enhancing the dataset:
| # | User | Score | Translations |
| 001 | Ayoub Boulmeghras | 1200 | 120 |
| 002 | Mohamed Ouaicha | 1100 | 110 |
| 003 | Moussa Aoukacha | 1050 | 105 |
| 004 | Yassir Salmi | 1030 | 103 |
| 005 | Anas Aberchih | 1020 | 102 |
| 006 | Mohamed Ait Hassoun | 820 | 82 |
| 007 | Akram Elmouden | 480 | 48 |
| 008 | El-houssaine Ohssine | 400 | 40 |
| 009 | Kawtar Khallouq | 130 | 13 |
| 010 | Ajidah Ski | 70 | 7 |
Conclusion
By leveraging collective knowledge and fostering community participation, Darija AI aims to create a rich, nuanced, and authentic resource for Darija-English translation. This approach paves the way for more accurate and contextually appropriate language models and translation tools, while simultaneously preserving and celebrating the unique characteristics of Moroccan Darija. Through this innovative crowdsourcing platform, we are not only building a valuable linguistic resource but also engaging the Darija-speaking community in the process of documenting and preserving their language in the digital age.
By implementing this Peer-Driven Validation process, we ensure that our Darija-English dataset is not just extensive, but also accurate, nuanced, and reflective of the true diversity of Moroccan Darija. This collaborative approach to quality assurance supports the continuous improvement of our dataset, making it an increasingly valuable resource for developing sophisticated language models and translation tools for Darija.
We invite all interested contributors, whether language enthusiasts or skilled developers, to join us in this exciting endeavor. Together, we can build a comprehensive, high-quality Darija-English dataset that will serve as a foundation for advanced language technologies, bridging linguistic gaps and preserving the rich cultural heritage embedded in Moroccan Darija.


